Системный анализ
С 2004 года занимался созданием web-сайтов как системный аналитик и разработчик. В числе них: собственный проект - сайт и база данных фигурного катания России, рабочие коммерческие проекты - сайты Детской футбольной лиги России и международного турнира UTLC Cup, сайты эстонской фигуристки Елены Глебовой и российского футболиста Валерия Леонова. На всех проектах собирал или формулировал бизнес-требования, разрабатывал технические задания или планы реализации. Подробнее о проектах.
Инженерия и анализ данных
Много лет стремлюсь систематизировать и анализировать данные. Изучаю разработку на Python (Django) и работу с Big Data. Создаю свои датасеты по аэропортам России и самолётному парку авиакомпаний, баскетболу, электростанциям, НПЗ, городам. В 2021 году работал аналитиком данных в одной из крупнейших лизинговых компаний России - «Европлан», а в 2022-м - в «Альфа-Банке».
Базы данных и SQL
Опыт работы с SQL с 2004 года.
СУБД: Greenplum, PostgreSQL (PL/pgSQL), MS SQL (T-SQL), Oracle, MySQL, ClickHouse, MongoDB.
Свой проект, созданный самостоятельно: база данных фигурного катания России
Использую:
- Разные виды джоинов (inner join, left join)
- Агрегатные функции (count, sum, avg, max, min)
- Оконные функции (ранжирующие - row_number, dense_rank; смещения - first_value, last_value, lag)
- Временные таблицы
- Общие табличные выражения (CTE)
- Выражения case, coalesce, nullif
- Вложенные запросы
- Предикат [not] exists
- Поля JSON
- Индексы (create [unique] index)
- Анализ таблицы (analyze)
- Хранимые процедуры на MS SQL Server и PostgreSQL
Python
Парсинг данных игроков чемпионата России по футболу 2020/21 с сайта Championat.com: Python+Jupyter Notebook (успешное тестовое задание на разработчика аналитических систем)
Фреймворки: PySpark, Django (в процессе изучения)
Библиотеки для работы с данными: pandas, NumPy
Библиотеки для визуализации: Matplotlib, Seaborn, Plotly
Прочие библиотеки: Beautiful Soup
ML-библиотеки: Scikit-learn (fit/predict, построение моделей - дерево решений, логистическая регрессия и случайный лес). Делал кластеризацию клиентов с помощью KMeans.
Основные инструменты - VS Code и Jupyter Notebook, а также PyCharm.
Для проверки гипотез использовал тесты: t-критерий Стьюдента, U-критерий Манна - Уитни, Z-тест.
Исследования
Исследование объявлений о продаже квартир в Санкт-Петербурге и Ленинградской области: Python+Jupyter Notebook (учебный проект)
Презентация
Графики в Numbers:
Статистика аэропортов и авиакомпаний (собственное исследование):
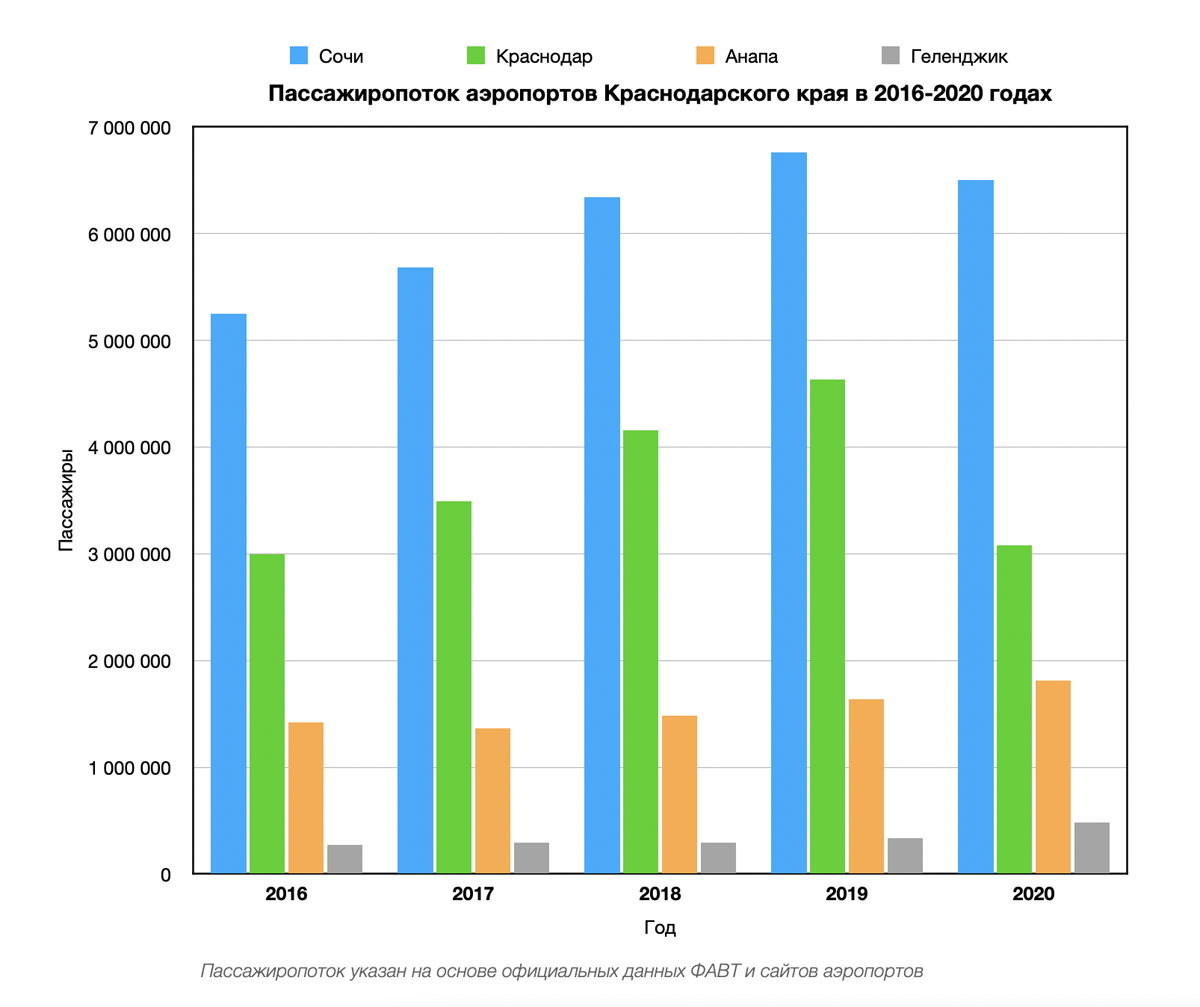
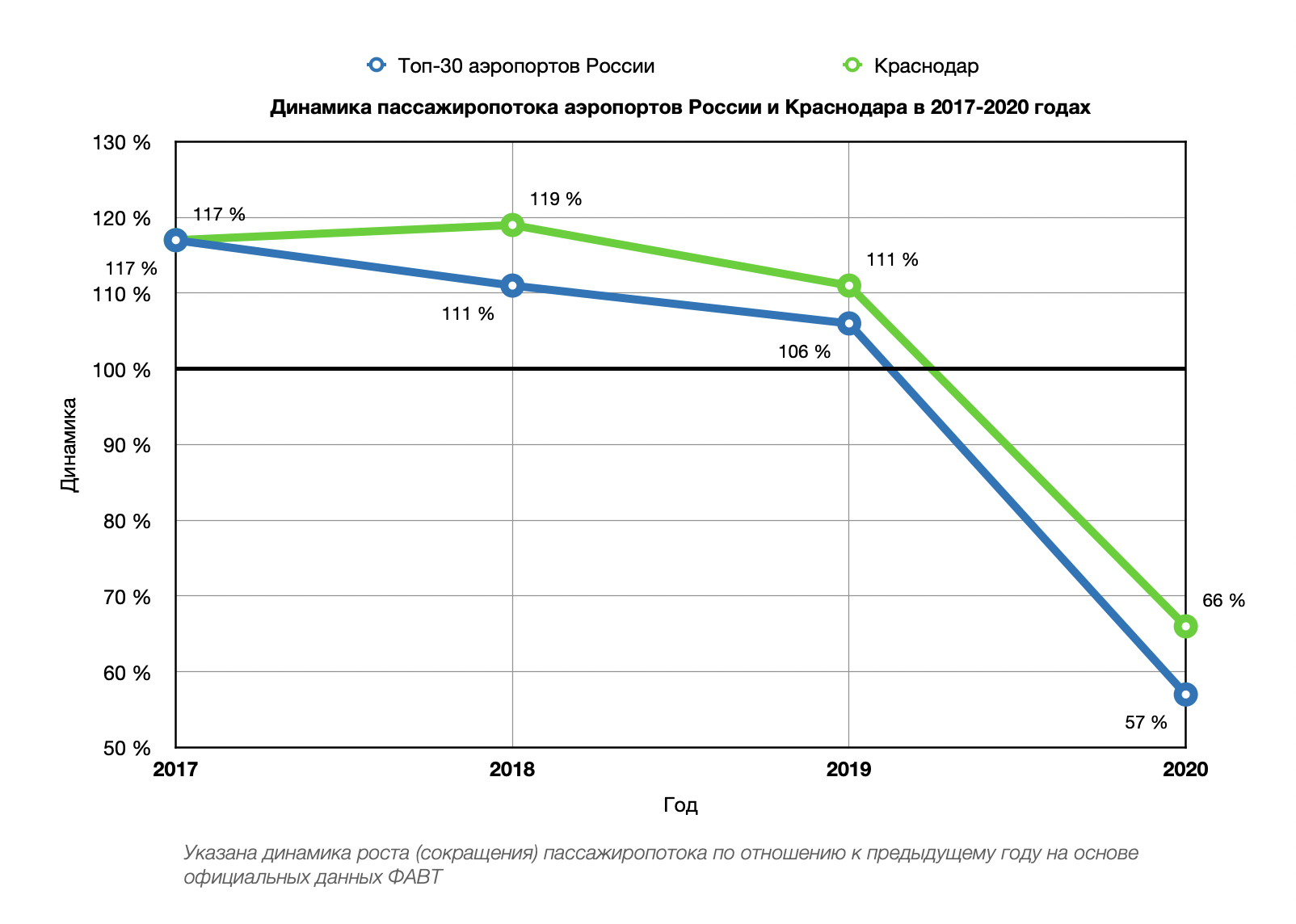
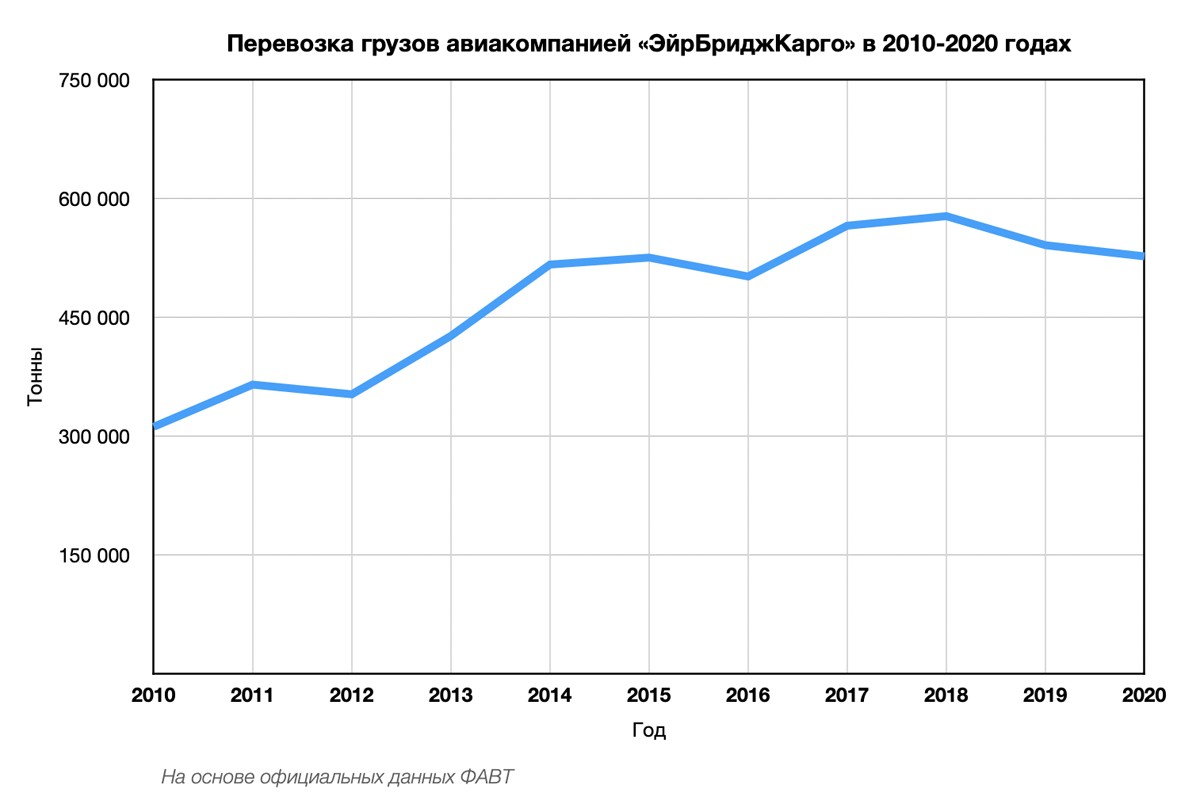
Tableau:
Дашборд со статистикой авиакомпаний России (собственное исследование)
Курсы
Яндекс.Практикум:
- «Инженер данных (Data Engineer)» (бета 6-месячного курса)
Karpov.Courses
- Docker, мини-курс
Stepik
- Постановка задачи на разработку ПО
- Введение в Data Science и машинное обучение (Анатолий Карпов)
- Основы статистики (Анатолий Карпов)
Прочие
- Мини-курс Брайана Кукси «Введение в API»
